Certain types of metrics only make sense when calculated at very specific levels of aggregation. One example is Candidate Scorecards (aka Interviewee Scorecards). Many Interviewing applications have a concept of Scorecards, where each interviewer rates the Candidate on one or more Skills. This data needs to be aggregated at different levels for different audiences. For e.g. the Functional Manager may want to see how each of the Interviewer rated the Candidate in each of the Skills. Whereas the HR way just want to see the Average by Skill. In contrast, Upper Management may just want to see the overall Average score for each Candidate.
This is where Semantic Views come into play. Let’s take an example following of a Candidate Scorecard where a Candidate (Uroosa) was interviewed by two Interviewers (Fatima and Hannah).
Here is the raw score data:
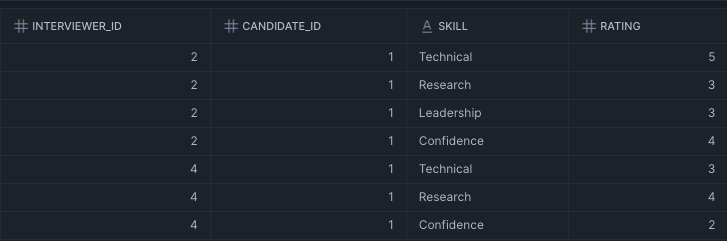
We will start with creating the sample dataset and a Semantic View that can perform aggregations at the aforementioned grains
use scratch.saqib_ali;
create or replace table interview_rating (interviewer_id int, candidate_id int, skill string, rating int);
create or replace table person (person_id int, person_name string);
insert into interview_rating values
(2, 1, 'Technical', 5)
, (2, 1, 'Research', 3)
, (2, 1, 'Leadership', 3)
, (2, 1, 'Confidence', 4)
, (4, 1, 'Technical', 3)
, (4, 1, 'Research', 4)
, (4, 1, 'Confidence', 2);
insert into person values
(1, 'Uroosa') -- Candidate
, (2, 'Fatima') -- Interviewer
, (3, 'Maryam') -- Interviewer
, (4, 'Hannah') -- Interviewer
, (5, 'Zainab'); -- Interviewer
Now let’s create a Semantic View:
CREATE OR REPLACE SEMANTIC VIEW candidate_scorecard
TABLES (
interviewer AS person PRIMARY KEY (person_id),
candidate AS person PRIMARY KEY (person_id),
interview_rating AS interview_rating PRIMARY KEY (interviewer_id, candidate_id, skill)
)
RELATIONSHIPS (
interview_rating (interviewer_id) REFERENCES interviewer
, interview_rating (candidate_id) REFERENCES candidate
)
DIMENSIONS (
interview_rating.skill AS skill,
candidate.candidate AS person_name,
interviewer.interviewer AS person_name
)
METRICS (
interview_rating.average_rating AS avg(rating)
)
;
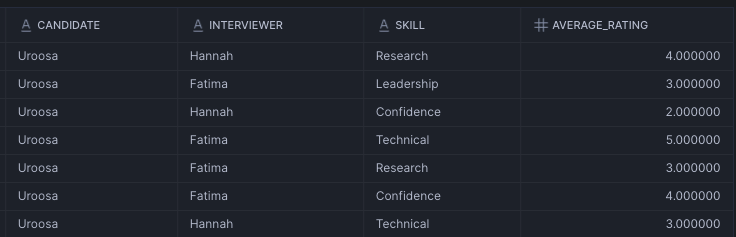
We can use this Semantic View to get aggregations at different level. For e.g. if we want to get individual scores by each interviewer for each skill (Functional Manager use case) we can use the following query:
SELECT * FROM SEMANTIC_VIEW(
candidate_scorecard
DIMENSIONS
candidate.candidate
, interviewer.interviewer
, interview_rating.skill
METRICS interview_rating.average_rating
);
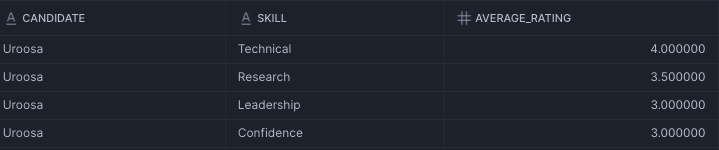
If we want to get the Average Rating for each Skill (HR use case) we can use the following query:
SELECT * FROM SEMANTIC_VIEW(
candidate_scorecard
DIMENSIONS
candidate.candidate
-- , interviewer.interviewer
, interview_rating.skill
METRICS interview_rating.average_rating
);
If we want to get the overall Average Score for the Candidate (Upper Management use case) we can use the following query:
SELECT * FROM SEMANTIC_VIEW(
candidate_scorecard
DIMENSIONS
candidate.candidate
-- , interviewer.interviewer
-- , interview_rating.skill
METRICS interview_rating.average_rating
);

Note that to aggregate at each of the above level we only had to change the DIMENSIONS in the Semantic View query. Semantic Views determine appropriate granularity based on dimensional attributes in the query. This is the power of the Semantic Views.