In the recent years Return Fraud has been on the rise. Once a return fraud has been detected, the information is used to create a network of the customers + addresses associated with the original transactions where the returned fraud was originally detected.
For e.g. let’s take the Network 2 below. Assume Eve commits a Return Fraud. Now we need to find all the addresses that Eve has used, and all the Customer have used that sames address and any other addresses associated with those Customers
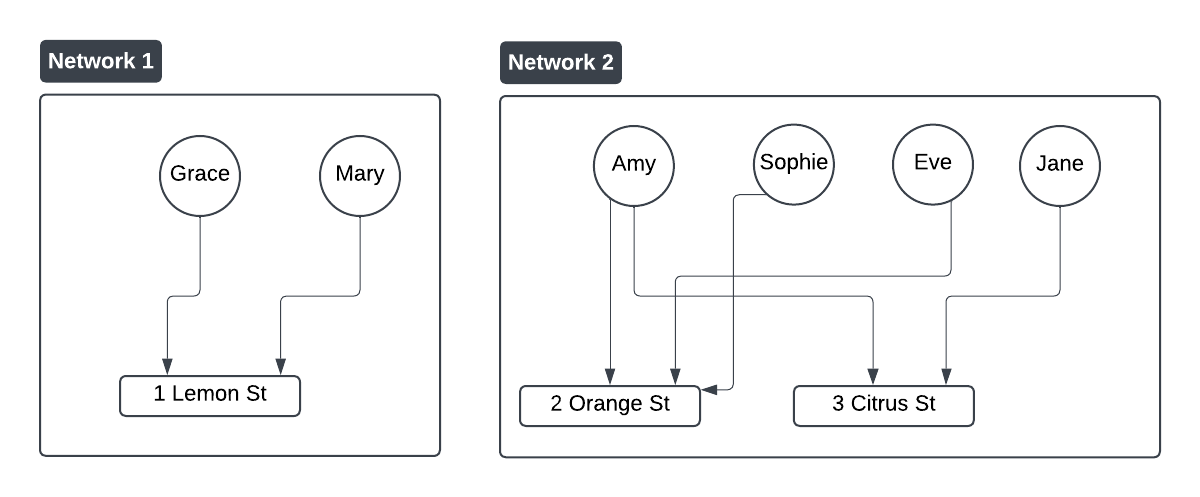
- Note that Eve never used 3 Citrus St, but it is used by Amy who shared an address with Eve i.e. 2 Orange St.
- Also, note that Jane has no direct link with Eve. However, she used the same address as Amy, and Amy and Eve had a address in common.
Formation of these networks is key to fraud analysis and understand the extend of the fraud. This type of analysis is well suited for Graph databases. We will look at how this can be achieved using Property Graphs (SQL/PGQ). Let’s start with some sample data.
CREATE TABLE customer (
customer_id int
, customer_name VARCHAR(400)
);
CREATE TABLE address (
address_id int
, full_address varchar(1000)
);
create table customer_address (
id int
, customer_id int
, address_id int
);
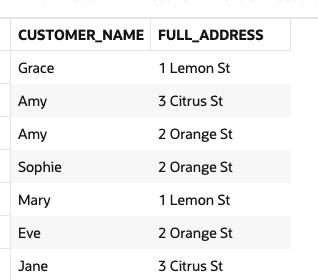
insert into CUSTOMER values (111, 'Grace'), (222, 'Amy')
, (333, 'Sophie'), (444, 'Mary')
, (555, 'Eve'), (6, 'Jane');
insert into address values(1, '1 Lemon St'), (2, '2 Orange St'), (3, '3 Citrus St');
insert into customer_address values(1, 111, 1), (2, 444, 1)
, (3, 222, 3), (4, 222, 2)
, (5, 333, 2), (6, 555, 2)
, (7, 666, 3);
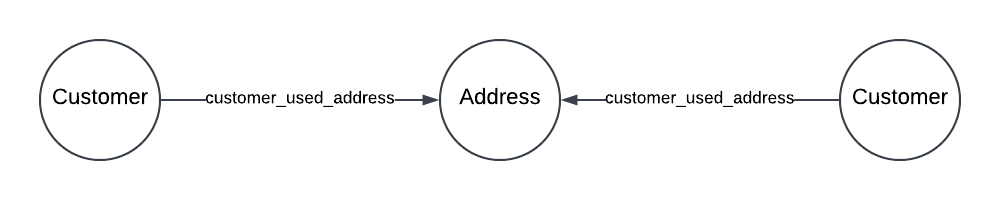
Let’s start with build a Property Graph that links Customer to Customer based on the Shared Address
create or replace PROPERTY graph customer_address_graph
VERTEX TABLES (
customer KEY (customer_id) PROPERTIES ARE ALL COLUMNS,
address KEY (address_id) PROPERTIES ARE ALL COLUMNS
)
EDGE TABLES (
customer_address as customer_used_address
KEY (id)
SOURCE KEY (customer_id ) REFERENCES customer(customer_id)
DESTINATION KEY (address_id) REFERENCES address(address_id)
PROPERTIES ARE ALL COLUMNS
);
Next let’s query this property graph and store the result as a table called shared_addresses.
create table shared_addresses as
select *
from GRAPH_TABLE(customer_address_graph
match (c1 is customer) - [e1 is customer_used_address] -> (shared_address is address)
<- [e2 is customer_used_address] - (c2 is customer)
where c1.customer_id <> c2.customer_id
columns (c1.customer_id as customer1_id
, c2.customer_id as customer2_id
, shared_address.full_address as shared_address)
);
Next build out the Property Graph that help in creating the Network
CREATE or replace PROPERTY GRAPH CUSTOMER_ADDRESS_NETWORK
VERTEX TABLES (
customer KEY (customer_id) PROPERTIES ARE ALL COLUMNS
)
EDGE TABLES (
shared_addresses as customer_is_related_to
KEY (customer1_id, shared_address, customer2_id)
SOURCE KEY (customer1_id ) REFERENCES customer(customer_id)
DESTINATION KEY (customer2_id ) REFERENCES customer(customer_id)
PROPERTIES ARE ALL COLUMNS
);
Finally let’s query this Property Graph
select distinct
listagg(distinct customer2_name, ', ') as customers
, listagg (distinct address.FULL_ADDRESS, ', ') as addresses
from GRAPH_TABLE(CUSTOMER_ADDRESS_NETWORK
match (c1 is customer) -[e1 is customer_is_related_to] - {, 5} (c2 is customer)
columns (c1.customer_id as customer1_id
, c2.customer_name as customer2_name
, c2.customer_id as customer2_id)
)
inner join customer_address on customer2_id = customer_address.CUSTOMER_ID
inner join address on customer_address.address_id = address.ADDRESS_ID
group by customer1_id;
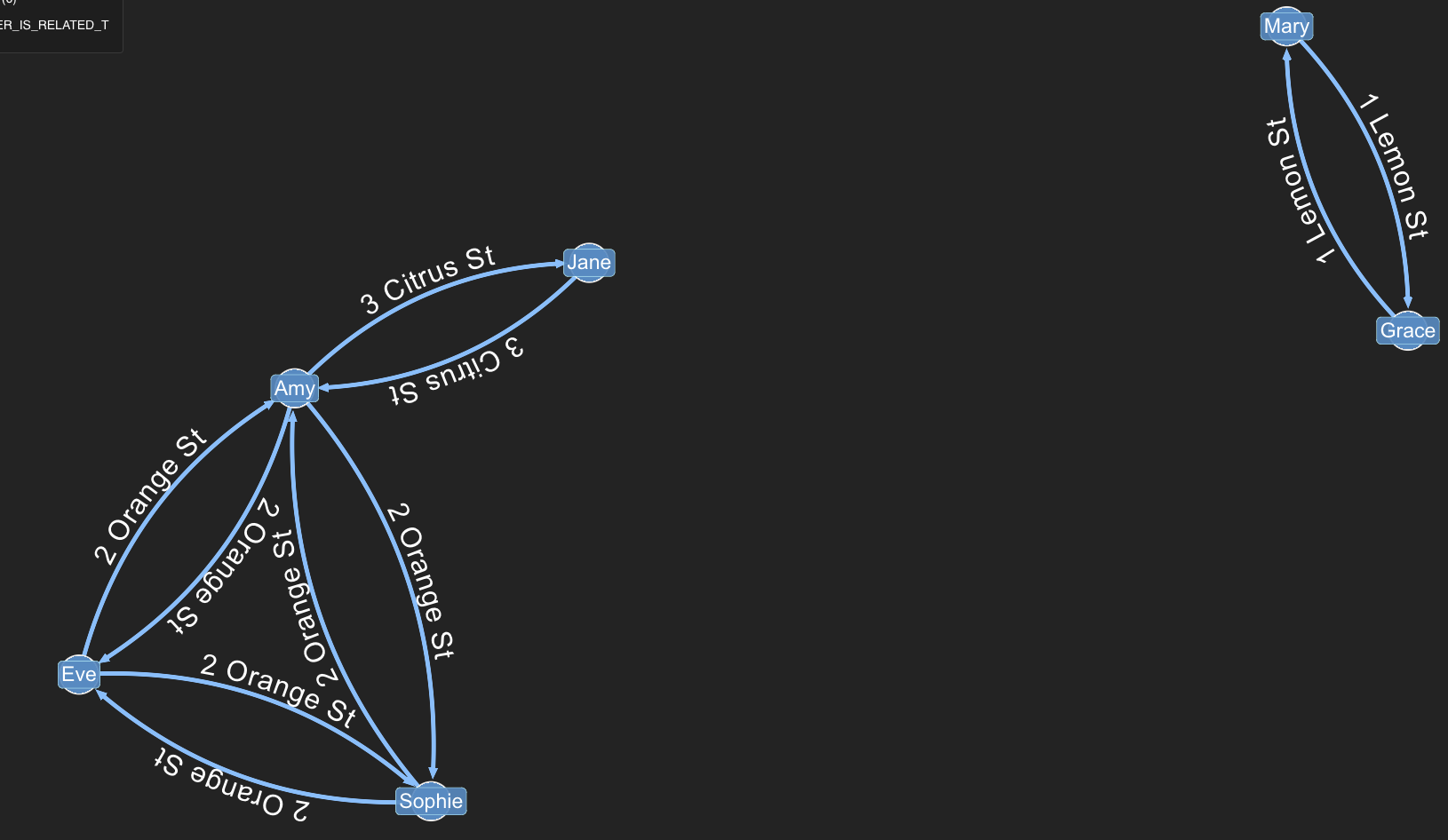
Here is the output of the Property Graph query. As you can see the Customers and Addresses have been clustered into Networks

Acknowledgments:
- Property Graph visualizations were created using G.V() – Graph Database Client & Visualization Tool